Wie Computer Vision die Erkennung von Apfelblütenstadien vereinfacht
Mithilfe eines speziell entwickelten KI-Modells zur Bildanalyse arbeiten wir an einer automatisierten und präzisen Erkennung der Entwicklungsstadien von Apfelblüten. Auf einer Apfelplantage in Sachsen erheben wir Bilddaten zum Training von Deep Learning Methoden und zeigen, wie wir die Arbeit von Landwirten mit Computer Vision erleichtern können. Da die Blühphasen regional variieren, erschwert es die optimale Steuerung von Düngung, Bewässerung und Schädlingsbekämpfung. Unser entwickeltes Modell erzielt dabei eine hohe Genauigkeit und schafft damit eine wichtige Grundlage für eine effizientere Bewirtschaftung. In diesem Blogbeitrag erklären wir, wie diese Technologie funktioniert.
Von Xuan Khanh Nguyen, Martin Schieck und Tobias Nolting
Ausgangspunkt
Mit dem Frühjahr beginnt auf dem Experimentierfeld von EXPRESS in Meißen die entscheidende Phase der Pflanzenentwicklung. Während einige Bäume bereits blühen, hinken andere aufgrund regionaler Unterschiede hinterher. Wie genau lassen sich solche Unterschiede erkennen? Welche Stadien sind bereits erreicht, und was bedeutet das für die optimale Versorgung der Pflanzen? Wie kann Computer Vision dabei helfen, diese Entwicklungsphasen effizient zu überwachen?
Erfassung des BBCH
Die BBCH-Skala, ein standardisiertes Klassifikationssystem, beschreibt die Entwicklungsstadien von Pflanzen wie der Apfelblüte. Die Stadien 53 bis 71 markieren wichtige Zeitpunkte: von der Knospenöffnung bis zur vollen Blüte. Wer diese Stadien kennt, kann gezielt landwirtschaftliche Maßnahmen ergreifen. Beispielsweise sollte in den BBCH-Stadien 57 bis 65 der gezielte Einsatz von Pestiziden erfolgen, da die Blüten in diesem Zeitraum besonders anfällig für Schädlinge und Pilzkrankheiten sind. Ein frühzeitiger Einsatz vor diesen Stadien ist weniger effektiv, da die Knospen noch geschützt sind. Ebenso ist es nicht ratsam, nach diesen Stadien Insektenschutzmittel aufzutragen, um bestäubende Insekten wie Bienen nicht zu gefährden.
Bisher basiert die Erkennung der Apfelblütenstadien hauptsächlich auf der Erfahrung der Landwirte und regelmäßigen, zeitintensiven Kontrollen vor Ort. Diese manuelle Methode birgt jedoch mehrere Herausforderungen: Zum einen erfordert sie geschultes Fachpersonal, welches die unterschiedlichen Entwicklungsstadien sicher bestimmen kann. Bei großen Plantagen mit mehreren Hektar Fläche ist dieser Aufwand kaum zu bewältigen, vor allem wenn Fachkräfte fehlen oder zeitlich stark ausgelastet sind. Zum anderen können regionale Unterschiede innerhalb einer Plantage – etwa durch Mikroklimata oder variierende Bodenbeschaffenheiten – zu ungleichen Blühphasen führen.
Durch die automatisierte Analyse der Bilddaten mit speziell trainierten Convolutional Neural Networks (CNN) lassen sich die Blüten schnell und präzise klassifizieren. Diese KI-Modelle sind darauf spezialisiert, Muster und Merkmale in Bilddaten zu erkennen und zu analysieren. Durch mehrere Schichten von Filtern werde die Bildinformationen Schritt für Schritt verarbeitet – von einfachen Formen bis hin zu komplexen Details wie der Struktur einer Blüte. So entsteht eine fundierte Grundlage, um differenzierte Entscheidungen für jede Teilfläche der Plantage zu treffen.
Aus diesem Grund wird mithilfe von handelsüblichen Blink RGB-Kameras ein umfassender Bilddatensatz der Blütenentwicklung erstellt und annotiert. Es werden Bilder der Apfelblüten aus unterschiedlichen Perspektiven aufgenommen, um eine möglichst große Vielfalt an Ansichten zu erfassen (Abb. 1). Anschließend erfolgt die Annotation der Bilder, bei der die einzelnen Blütenstadien gemäß der BBCH-Skala manuell gekennzeichnet und den entsprechenden Klassen zugeordnet werden. Daraufhin werden die Bilddaten für das CNN-Modell vorbereitet und trainiert, um die entsprechenden BBCH-Stadien anhand eines neuen unbekannten Apfelblütenbildes vorherzusagen
Abbildung 1: zeigt Beispiele für Bilder, die aus unterschiedlichen Perspektiven aufgenommen wurden, um eine möglichst große Variabilität der Apfelblütenstadien zu erfassen. Die verschiedenen Blickwinkel – von oben, seitlich und direkt unter den Blüten – stellen sicher, dass das KI-Modell mit vielfältigen Daten trainiert wird. Diese Herangehensweise erhöht die Robustheit des Modells, da es lernt, die Entwicklungsstadien der Apfelblüten unabhängig von Perspektive, Lichtverhältnissen oder Kamerawinkel zuverlässig zu erkennen und zu klassifizieren.
Versuchsablauf
Über einen Zeitraum von April bis Juli 2023 wurden auf dem Experimentierfeld in Meißen täglich von Sonnenaufgang bis Sonnenuntergag Bilder aufgenommen. Dazu wurden insgesamt 30 Blink RGB-Kameras installiert, die stündlich Bilder der Apfelblüten lieferten. So entstand ein Datensatz, der mehr als 19.000 Bilder umfasste.
Dieser umfangreiche Datensatz musste zunächst bereinigt und manuell über CVAT annotiert werden. So wurden überbelichtete Bilder und Bilder mit zu wenig Detail verworfen. Das semi-automatische Annotationswerkezug Segment Anything unterstützte den Prozess, indem es die Einteilung erleichterte. Ein wichtiger Bestandteil der Datenvorbereitung war die Augmentation der Bilder, um die Variabilität der Trainingsdaten zu verbessern. Dazu wurden die Bilder beispielsweise horizontal und vertikal verschoben, um unterschiedliche Positionierungen der Blüten zu simulieren. Zusätzlich wurden sie gedreht und mit Skalierungen sowie Scherungen verzerrt, um perspektivische Unterschiede abzubilden.
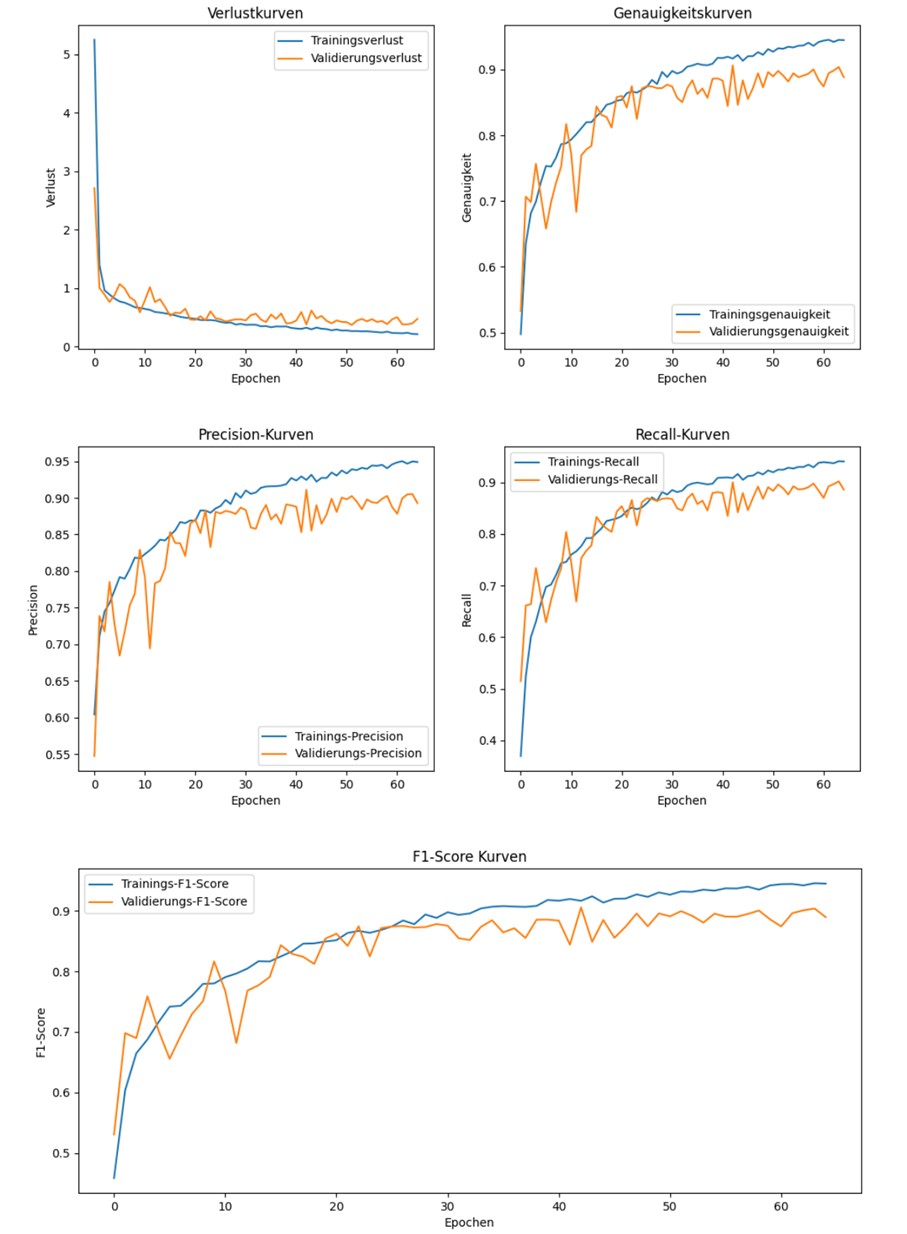
Auf dieser Basis begann die Modellentwicklung. Es wurden verschiedene CNN-Modelle getestet, die darauf trainiert wurden, die Bilddaten den entsprechenden Blütenstadien zuzuordnen. Um die Leistung der Modelle zu bewerten, kamen verschiedene Metriken zum Einsatz: Genauigkeit, Präzision, Recall (Trefferquote), der F1-Score sowie die Trainingszeit. Diese Kriterien ermöglichten einen klaren Vergleich der Modelle hinsichtlich ihrer Effizienz und Präzision (Abb. 2).
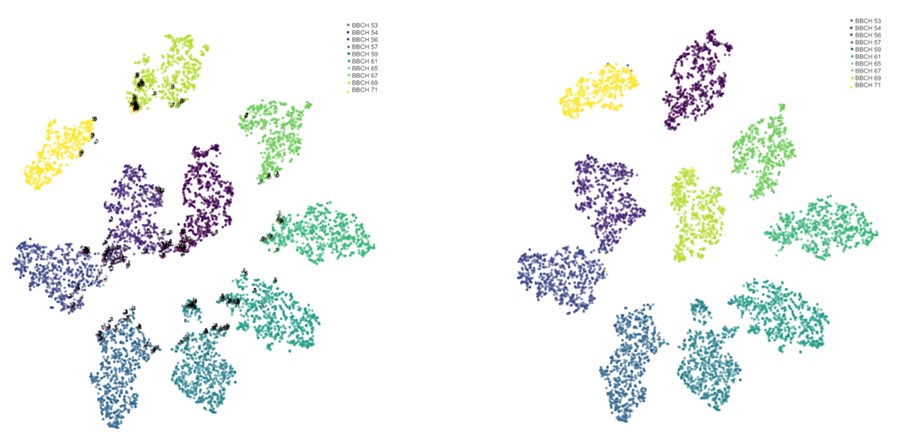
Ein weiterer Schritt zur Verbesserung der Ergebnisse war die Optimierung mithilfe der t-SNE-Methode. Dieses Verfahren wurde genutzt, um Fehlannotationen im Datensatz zu identifizieren. Dabei projizierte t-SNE die hochdimensionalen Bilddaten in einen niedrigdimensionalen Raum und machte Bilder sichtbar, die trotz Ähnlichkeit verschiedenen Kategorien zugeordnet waren (Abb. 3). Durch manuelle Überprüfung und Korrektur dieser Fehler konnte die Genauigkeit des Modells um 2% gesteigert werden.
Die Ergebnisse zeigten, dass die CNN-Architektur MobileNet die beste Leistung erzielte. Es überzeugte durch eine hohe Genauigkeit von 93,1%. Damit erwies sich MobileNet als besonders effizient und geeignet für ressourcenbeschränkte Umgebungen, wie etwa den Einsatz in mobilen Anwendungen oder auf kleineren Betriebssystemen.
Abbildung 2: Die Abbildung zeigt die Performanzkurven des MobileNet-Modells für Trainings- und Validierungsdaten über 60 Epochen. Insgesamt lässt sich erkennen, dass das Modell schnell lernt und eine hohe Genauigkeit erreicht. Die Verlustkurven zeigen eine starke Abnahme zu Beginn des Trainings, bevor sie sich stabilisieren. Der Validierungsverlust bleibt etwas höher, was auf eine leichte Überanpassung hinweist, jedoch in einem akzeptablen Rahmen bleibt. Die Genauigkeitskurven verdeutlichen, dass das Modell im Training kontinuierlich besser wird und schließlich etwa 94% Genauigkeit erreicht, während die Validierungsgenauigkeit stabil bei etwa 90% liegt. Auch die Precision-, Recall- und F1-Score-Kurven folgen diesem Verlauf: Die Werte steigen zu Beginn zügig an und stabilisieren sich danach auf einem hohen Niveau.
Zeitersparnis in der BBCH Erkennung
Die Überwachung der Apfelblütenstadien durch CNNs zeigt, wie KI-Technologien die Landwirtschaft optimieren kann. Während bislang die Bestimmung der Entwicklungsstadien zeitintensive manuelle Kontrollen erforderte, bietet das entwickelte CNN-Modell eine schnelle und zuverlässige Alternative. Die präzise Erkennung erlaubt eine ressourceneffiziente Steuerung von Düngung, Bewässerung und Schädlingsbekämpfung.
Eine besondere Betrachtung war die Anwendung von t-SNE. Diese Technik half dabei, verborgene Fehler in den Daten zu finden. Durch die Projektion der Bilddaten in einen zweidimensionalen Raum entstanden Cluster, die visuell klar abgrenzbare Gruppen zwischen den BBCH-Stadien darstellten. Die t-SNE-Analyse lieferte wertvolle Einblicke in die Datenqualität und zeigte, wie klar die Entwicklungsstadien der Blüten voneinander getrennt werden können.
Ein weiterer interessanter Punkt ist die Flexibilität des MobileNet-Modells. Diese Architektur erfordert weniger Rechenleistung als vergleichbar akkurate Modelle und kann daher auch in mobilen Anwendungen eingesetzt werden. Das bedeutet: Landwirte könnten in Zukunft mit ihrem Smartphone oder Tablet live den Zustand ihrer Plantagen überwachen.
Der schwierigste Aspekt des Projekts war die Annotation der Bilddaten, die einen erheblichen Zeitaufwand erforderte. Jedes der über 19 000 Bilder musste manuell geprüft und den entsprechenden Entwicklungsstadien gemäß der BBCH-Skala zugeordnet werden. Dieser Schritt ist zwar sehr zeitintensiv und aufwendig, bildet jedoch die Grundlage für die Modellentwicklung. Einmal durchgeführt, bietet die sorgfältige Annotation jedoch einen dauerhaften Nutzen, da die erstellten Datensätze für das Training und die Validierung des Modells wiederverwendet werden können. Zudem ermöglicht eine präzise Annotation langfristig zuverlässige Ergebnisse und trägt entscheidend zur Leistungsfähigkeit und Genauigkeit des KI-Modells bei.
Das zentrale Take-Away dieser Entwicklung ist, dass mithilfe von Computer Vision bei der Erkennung von Apfelblütenstadien Zeit gespart werden kann und Ressourcen effizienter genutzt werden können, ohne die Genauigkeit zu vernachlässigen.
Abbildung 3: zeigt die t-SNE-Cluster vor (links) und nach (rechts) der Bereinigung der Fehlannotationen. Vor der Bereinigung (links) sind die Cluster noch unsauber und teilweise überlappend, was darauf hinweist, dass einige Bilder fälschlicherweise den falschen BBCH-Stadien zugeordnet wurden. Diese Fehlzuordnungen erschweren die klare Trennung der Entwicklungsstadien und reduzieren die Genauigkeit des Modells. Nach der Bereinigung (rechts) sind die Cluster deutlich klarer abgegrenzt, und die einzelnen Entwicklungsstadien der Apfelblüten (BBCH 53 bis BBCH 71) lassen sich besser separieren. Die Datenbereinigung hat somit dazu geführt, dass die Fehlannotationen korrigiert und die Datenqualität verbessert wurden. Dies trägt maßgeblich zur höheren Genauigkeit des Modells bei, da die Trainingsdaten jetzt präziser und konsistenter sind.
Ausblick
Die Ergebnisse dieser Entwicklung stellen einen großen Schritt in Richtung digitaler Landwirtschaft dar. Doch was bedeutet das konkret für die Zukunft?
Kurzfristig können Landwirte durch den Einsatz dieser Technologie ihre Erträge steigern, indem die Apfelblütenstadien präzise bestimmt werden. Dies führt zu wirtschaftlichen Vorteilen und ermöglicht auch ein umweltschonenderes Arbeiten, da unnötige Einsätze von Betriebsmitteln gemindert werden.
Der Einsatz von künstlicher Intelligenz zur Erkennung von Pflanzenstadien ist ein praktisches Werkzeug, das Landwirten die Arbeit erleichtert. Diese Erprobung im Experimentierfeld EXPRESS zeigt, dass der Weg hin zu dieser digitalen Lösungen für die Praxis nicht mehr weit ist und bereits jetzt im Labor zuverlässig arbeitet. Mittelfristig könnten deshalb Echtzeit-Apps entwickelt werden, die den Zustand der Blüten direkt analysieren und den Landwirten Handlungsempfehlungen vor Ort liefern. Ein weiteres spannendes Potenzial besteht in der Erweiterung der KI-Modelle auf andere Obstsorten, wie beispielsweise Kirschen oder Pfirsiche, wodurch die Technologie noch breiter einsetzbar wird.
Haben Sie Fragen?
Martin Schieck
Datenintegration, Vernetzung und Projektmanagement Wirtschaftswissenschaftliche Fakultät der Universität Leipzig
Martin Schieck kennt sich nicht nur mit maschinellem Lernen und virtuellen Welten bestens aus, sondern ist im Rahmen von EXPRESS neuerdings auch in Sachen Birnenblattsauger unterwegs. Für das Projekt entwickelt der Wirtschaftsinformatiker unter anderem Lösungen in den Bereichen Vernetzung und Datenintegration oder Lösungen zur Erkennung von Schädlingsbefall.